Ollama 사용 방법 및 벤치마크 자료
목차
Ollama는 별도의 리포지토리를 통해 LLM 모델을 제공합니다. 종류에 대해서는 이곳을 통해 확인이 가능하며 한국어에 능통했던 LLM 모델과 사양은 아래와 같습니다.
|
참고사항 - 운영체제 : Ubuntu 24.04 - 7B 파라미터마다 8GB의 배수가 되는 DRAM or VRAM이 필요합니다. |
| 모델 | 파라미터 크기 | GPU VRAM 권장사양 | 명령어 |
|---|---|---|---|
| Gemma3 | 12B | 16GB | ollama run gemma3:12b |
| Gemma3 | 27B | 32GB | ollama run gemma3:27b |
| Phi4 | 14B | 16GB | ollama run phi4:14b |
run 옵션을 통해 LLM 모델이 작동하며 서버 내부에 파일이 없을 경우 다운로드가 진행 된 뒤 질문을 남길 수 있습니다.
| ollama run gemma3:27b |
| LLM 동작 |
|
>>> Send a message (/? for help) >>> 학습한 데이터는 몇년도 데이터인가요? >>> /bye |
ps 옵션을 통해 동작하는 모델의 내용과 상태를 확인할 수 있습니다.
| ollama ps |
|
NAME ID SIZE PROCESSOR UNTIL NAME : LLM 모델 이름 |
LLM 모델만을 다운로드 받고 싶을 경우 pull 옵션을 통해 진행할 수 있습니다.
| ollama pull phi4:14b |
| ollama ls |
|
NAME ID SIZE MODIFIED
|
| ollama stop gemma3:27b |
| ollama rm gemma3:27b |
Open WebUI와 연동하여 사용
Open WebUI는 실행 시 Ollama와 자동적으로 연동하여 편리하게 사용이 가능합니다. 먼저 서버에서 8080 포트가 활성화 되어있는지 확인합니다.
| netstat -nltp |
| tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 41666/python3 |
만일 8080 포트가 확인되지 않는다면 Open WebUI 서비스의 상태 체크가 필요합니다.
| systemctl status openwebui.service |
| http://xxx.xxx.xxx.xxx:8080 |
관리자가 될 계정정보를 입력 후 관리자 계정 생성을 클릭합니다.
모델 선택을 클릭하면 자신이 다운로드 받은 LLM 모델이 나열되거나 없다면 다운로드가 가능합니다. 가능하면 ollama pull 명령을 통해 터미널에서 다운로드 받는것을 권장 합니다.
phi4를 선택 후 질문을 남길 수 있습니다.
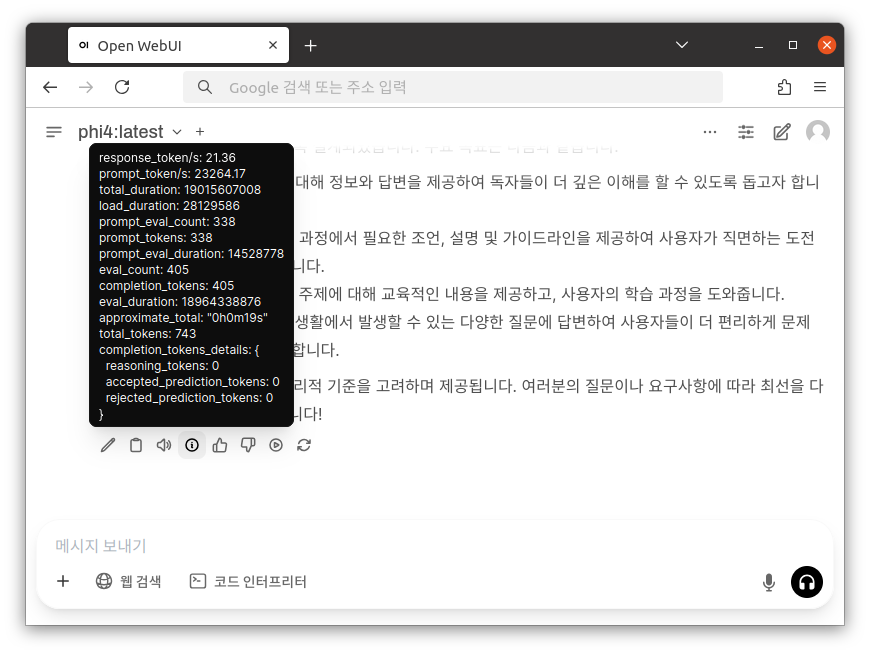
LLM 모델에 관한 성능 및 결과 값을 확인할 수 있습니다.
|
참고사항 서버와 Open WebUI에 기본적으로 사용되는 22, 8080 포트에 불필요한 외부 접근을 막고 안정적인 사용을 위해서 자체적인 설정 또는 매뉴얼 통한 방화벽 설정을 적용하여 사용할 것을 권장합니다. |
1. AMD AI W6800 BMv1 기준 벤치마크 자료
|
매개변수 |
양자화 |
크기 |
DRAM 사용량 |
VRAM 사용량 |
출력 Token/s |
컨텍스트 길이 |
|---|---|---|---|---|---|---|
|
Gemma3 12B |
Q4_K_M |
8.1GB |
1.5GB |
11GB |
34.21 |
128K |
|
Gemma3 27B |
Q4_K_M |
17GB |
2.4GB |
20.7GB |
16.85 |
128K |
|
DeepSeek-R1 7B |
Q4_K_M |
4.7GB |
0.5GB |
5.7GB |
54.97 |
128K |
|
DeepSeek-R1 14B |
Q4_K_M |
9.0GB |
0.5GB |
11.2GB |
31.42 |
128K |
|
DeepSeek-R1 32B |
Q4_K_M |
19GB |
0.5GB |
22.7GB |
16.29 |
128K |
|
DeepSeek-R1 70B |
Q4_K_M |
42GB |
1.1GB |
31GB |
2.58 |
128K |
|
Llama 4 – Scout 109B |
Q4_K_M |
67GB |
38GB |
29.2GB |
6 |
10M |
|
Llama 3.3 70B |
Q4_K_M |
42GB |
1GB |
31.1GB |
2.63 |
128K |
|
Llama 3.2 11B |
Q4_K_M |
7.8GB |
0.9GB |
11.8GB |
55.96 |
128K |
|
Llama 3.2 90B |
Q4_K_M |
54GB |
26.8GB |
31.5GB |
1.99 |
128K |
|
Phi4 14B |
Q4_K_M |
9.1GB |
0.5GB |
11.5GB |
34.73 |
16K |
|
HyperCLOVA X SEED 1.5B |
F16 |
3.2GB |
0.3GB |
4.6GB |
88.37 |
128K |
|
HyperCLOVA X SEED 3B |
Q4_K_M |
2.0GB |
0.6GB |
3.9GB |
92.82 |
128K |
2. AMD AI 9060XT BMv1 기준 벤치마크 자료
|
매개변수 |
양자화 |
크기 |
DRAM 사용량 |
VRAM 사용량 |
출력 Token/s |
컨텍스트 길이 |
|---|---|---|---|---|---|---|
|
Gemma3 12B |
Q4_K_M |
8.1GB |
2.2GB |
11GB |
30.84 |
128K |
|
Gemma3 27B |
Q4_K_M |
17GB |
6.7GB |
14.5GB |
7.58 |
128K |
|
DeepSeek-R1 7B |
Q4_K_M |
4.7GB |
1.3GB |
3.9GB |
44.6 |
128K |
|
DeepSeek-R1 14B |
Q4_K_M |
9.0GB |
1.4GB |
11.2GB |
28 |
128K |
|
DeepSeek-R1 32B |
Q4_K_M |
19GB |
1.6GB |
15.7GB |
5.52 |
128K |
|
DeepSeek-R1 70B |
Q4_K_M |
42GB |
2.2GB |
15.4GB |
1.87 |
128K |
|
Llama 4 – Scout 109B |
Q4_K_M |
67GB |
53.9GB |
13.5GB |
5.02 |
10M |
|
Llama 3.3 70B |
Q4_K_M |
42GB |
1.6GB |
15.4GB |
1.5 |
128K |
|
Llama 3.2 11B |
Q4_K_M |
7.8GB |
1.2GB |
11.7GB |
52.7 |
128K |
|
Llama 3.2 90B |
Q4_K_M |
54GB |
40.6GB |
15.6GB |
1.35 |
128K |
|
Phi4 14B |
Q4_K_M |
9.1GB |
0.7GB |
11.5GB |
29.55 |
16K |
|
HyperCLOVA X SEED 1.5B |
F16 |
3.2GB |
0.6GB |
4.6GB |
72.4 |
128K |
|
HyperCLOVA X SEED 3B |
Q4_K_M |
2.0GB |
1.4GB |
3.8GB |
84.4 |
128K |
3. AMD AI GPU K6 BMv1 기준 벤치마크 자료
|
매개변수 |
양자화 |
크기 |
DRAM 사용량 |
VRAM 사용량 |
출력 Token/s |
컨텍스트 길이 |
|---|---|---|---|---|---|---|
|
Gemma3 12B |
Q4_K_M |
8.1GB |
11.6GB |
8GB |
3.3 |
128K |
|
Gemma3 27B |
Q4_K_M |
17GB |
19.7GB |
8GB |
1.5 |
128K |
|
DeepSeek-R1 7B |
Q4_K_M |
4.7GB |
1.3GB |
8GB |
5.7 |
128K |
|
DeepSeek-R1 14B |
Q4_K_M |
9.0GB |
16GB |
8GB |
2.9 |
128K |
|
DeepSeek-R1 32B |
Q4_K_M |
19GB |
22GB |
8GB |
1.2 |
128K |
|
Llama 3.2 11B |
Q4_K_M |
7.8GB |
9GB |
8GB |
5 |
128K |
|
Phi4 14B |
Q4_K_M |
9.1GB |
12GB |
8GB |
2.4 |
16K |
|
HyperCLOVA X SEED 1.5B |
F16 |
3.2GB |
3GB |
8GB |
8 |
128K |
|
HyperCLOVA X SEED 3B |
Q4_K_M |
2.0GB |
2GB |
8GB |
11.9 |
128K |