Ktransformers 사용 방법 및 벤치마크 자료
목차
Ktransformers을 사용하기 위해서는 huggingface의 계정과 경우에 따라 LLM 모델의 리포지토리 사용 허가가 필요할 수 있습니다. 이 매뉴얼에서는 LLM 모델의 설정 방법과 Open WebUI를 연동하는 방법에 관해 소개합니다.
|
참고사항 - 운영체제 : Ubuntu 24.04 |
LLM 모델을 사용하려면 Hugging Face에서 다운로드가 필요합니다. 여기서는 예시로 DeepSeek-R1:671B 버전을 사용할 것으로 최소 400GB 이상의 디스크 용량을 확보 하시는 것을 권장드립니다.
먼저 가상환경을 활성화 후 ktransformers 디렉토리 내부에 llm_model 디렉토리를 생성합니다. OS 디스크의 용량이 충분하지 않다면 테스트 전 llm_model 디렉토리에 별도의 디스크를 마운트 해주세요.
| conda activate ktransformers mkdir -p /root/ktransformers/llm_model/ |
ktransformers 디렉토리 내부에서 작동할 DeepSeek-R1:671B 버전의 디렉토리를 생성하고 다운로드를 진행합니다.
| mkdir -p /root/ktransformers/llm_model/DeepSeek-R1-Q4_K_M cd /root/ktransformers/llm_model/DeepSeek-R1-Q4_K_M wget https://huggingface.co/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-0000{1..9}-of-00009.gguf |
ktransformers와 DeepSeek-R1:671B 버전은 대화 형식과 API 형식으로 작동 방법이 나뉘어 집니다. 원하는 부분을 참고하여 명령어 사용을 진행 합니다.
| 참고사항 - -cpu_infer 옵션은 사용하고 있는 서버의 최대 쓰레드에서 2를 뺀 내용으로 적용합니다. - LLM에 질문 시 별도의 터미널을 실행 후 curl 명령어를 사용해야합니다. |
LLM 모델 실행
| cd /root/ktransformers python -m ktransformers.local_chat --model_path deepseek-ai/DeepSeek-R1 --gguf_path /root/ktransformers/llm_model/DeepSeek-R1-Q4_K_M --cpu_infer 46 |
LLM 질문 방법
| curl http://localhost:10002/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-ai/DeepSeek-R1", "prompt": "대한민국의 수도가 어디야? 간단히 설명해줘", "max_tokens": 200 }' |
LLM 답변
|
{"id":"9935f4f6-b71c-4636-8f74-5ad73b062d16","object":"text_completion","created":1958054732,"choices":[{"index":0,"text":"\n\n대한민국의 수도는 서울특별시입니다. 서울은 한국의 정치, 경제, 문화의 중심지로, 한반도 서부 중앙에 위치하고 있습니다. 1948년 대한민국 정부 수립 이후부터 지금까지 수도 역할을 하고 있습니다. 서울은 인구 약 1천만 명의 거대 도시로, 전국 인구의 약 20%가 거주하고 있습니다. 주요 관광지로는 경복궁, 남산타워, 명동 등이 있으며, 한강이 도시를 가로지르고 있습니다.","logprobs":null,"finish_reason":null}],"model":"not implmented","system_fingerprint":"not implmented","usage":null} }' |
2-2. LLM 모델 실행 및 질문 방법(API 형식)
ktransformers와 DeepSeek-R1:671B 버전은 대화 형식과 API 형식으로 작동 방법이 나뉘어 집니다. 원하는 부분을 참고하여 명령어 사용을 진행 합니다.
| 참고사항 - --cpu_infer 옵션은 사용하고 있는 서버의 최대 쓰레드에서 2를 뺀 값으로 적용합니다. - LLM에 질문 시 별도의 터미널을 실행 후 curl 명령어를 사용해야합니다. |
LLM 모델 실행
| cd /root/ktransformers ktransformers --model_path deepseek-ai/DeepSeek-R1 --gguf_path /root/ktransformers/llm_model/DeepSeek-R1-Q4_K_M --port 10002 --max_new_tokens 8192 --cpu_infer 46 |
LLM 질문 방법
| curl http://localhost:10002/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-ai/DeepSeek-R1", "messages": [ {"role": "system", "content": "당신은 친절한 AI 입니다."}, {"role": "user", "content": "당신에 관해 간략하게 설명해주세요."} ] }' |
LLM 답변
| {"id":"c48avba48g86zn8t4ky86l48811238ta","object":"chat.completion","created":1785824865,"model":"DeepSeek-Coder-V2-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n아, 사용자가 저에 대해 간단한 설명을 요청하셨네요. 사용자는 아마도 저를 처음 접하셨을 테니 기본적인 소개가 필요할 것 같아요.</think>\n안녕하세요! \n저는 **DeepSeek-R1**이라고 해요저는 아직도 배우고 성장 중인 AI랍니다. \n**질문은 언제든 환영이에요!** \n지금 무엇을 도와드릴까요?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":24,"completion_tokens":736,"total_tokens":760,"prompt_tokens_details":null,"completion_tokens_details":null},"system_fingerprint":"fp_qsg8h8y6840z" |
Open WebUI와 연동하여 사용
Open WebUI에서 Ktransformers을 연동해서 사용하려면 몇가지 준비 과정이 필요합니다. 먼저 서버에서 8080 포트가 활성화 되어있는지 확인합니다.
| netstat -nltp |
| tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 41666/python3 |
만일 8080 포트가 확인되지 않는다면 Open WebUI 서비스의 상태 체크가 필요합니다.
| systemctl status openwebui.service |
Open WebUI에서 Ktransformers을 자동으로 연동하지 않으므로 2. LLM 모델 실행 및 질문 방법의 내용을 통해 터미널에서 지속적으로 실행이 되어야합니다.
| http://xxx.xxx.xxx.xxx:8080 |
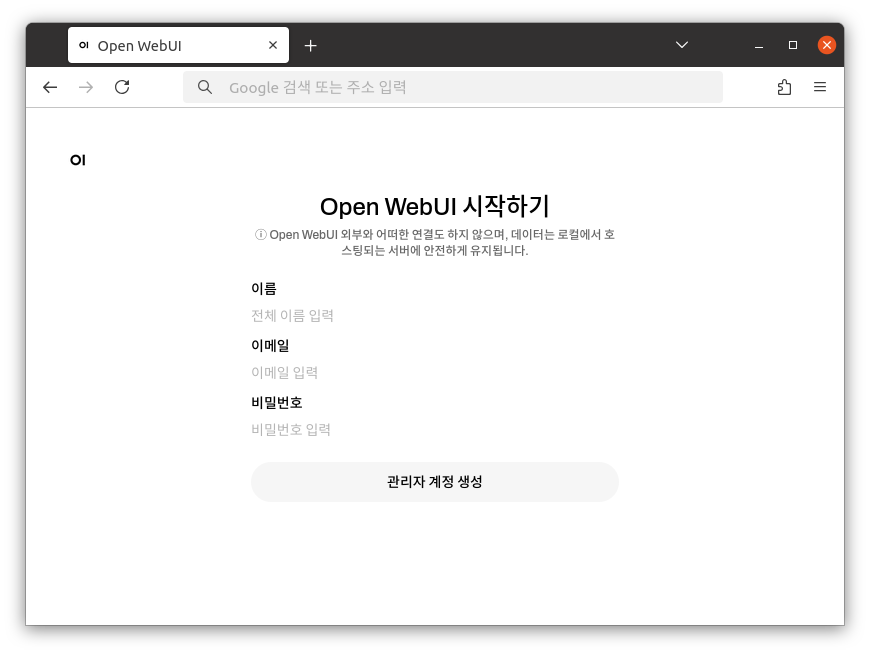
관리자가 될 계정정보를 입력 후 관리자 계정 생성을 클릭합니다.
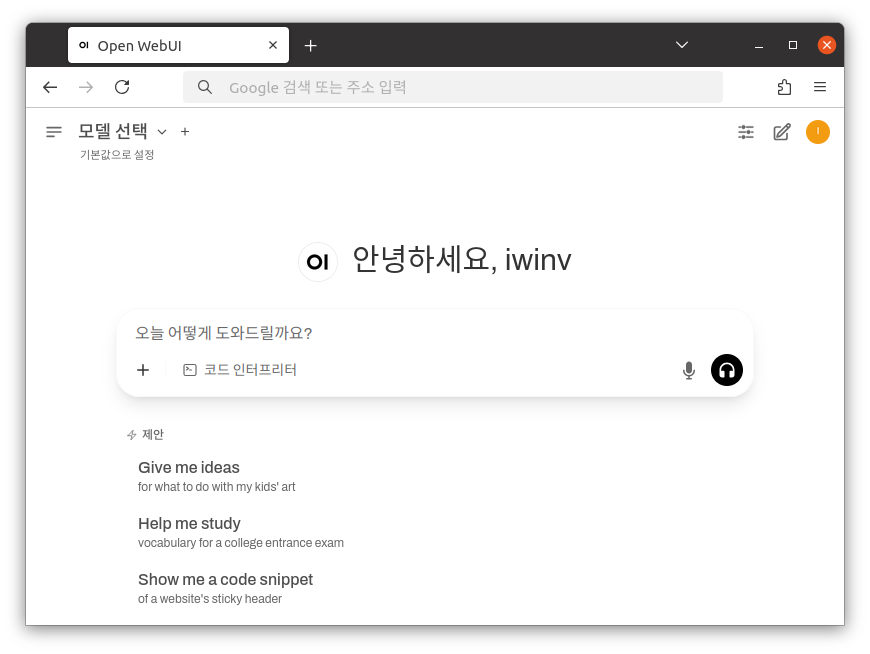
Ktransformers과 연동이 되어있지 않다면 모델 선택에서 내용을 확인할 수 없습니다.
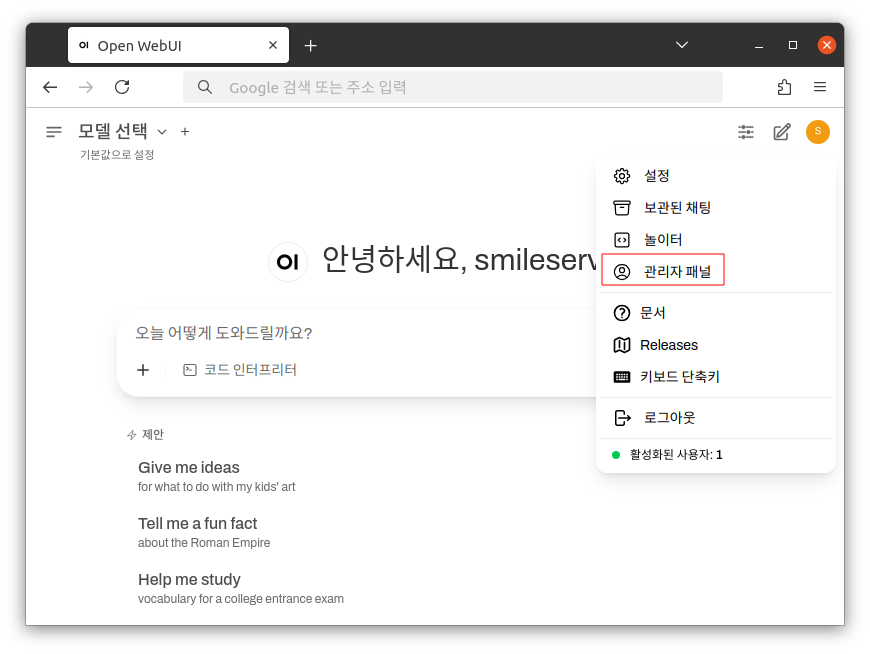
좌측 상단에 유저 아이콘을 클릭 후 사용자 패널로 이동합니다.
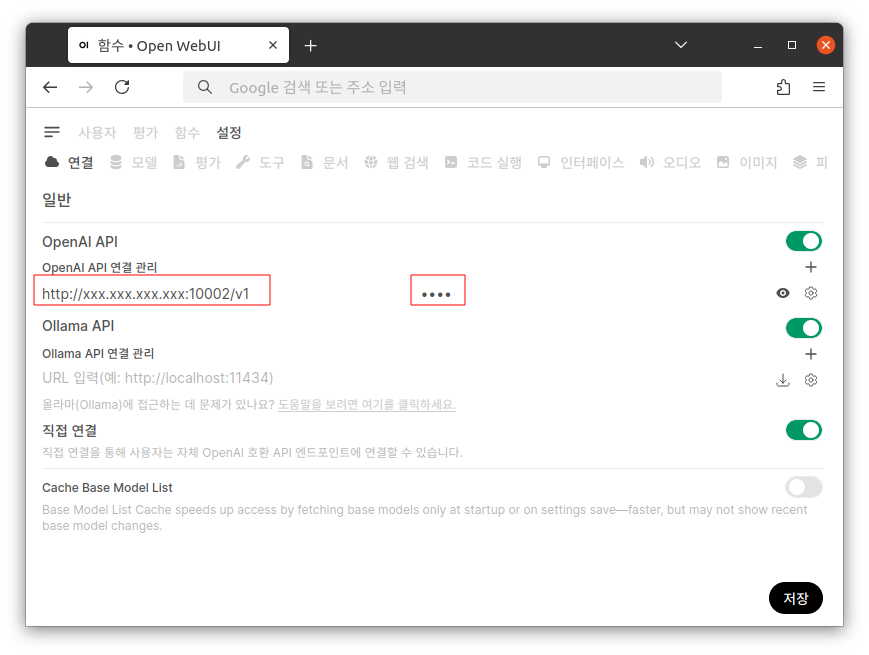
OpenAI API 연결 관리에서 아래와 같은 내용을 입력하고 저장합니다.
| URL : http://xxx.xxx.xxx.xxx:10002/v1 비밀번호 : 임의의 값 |
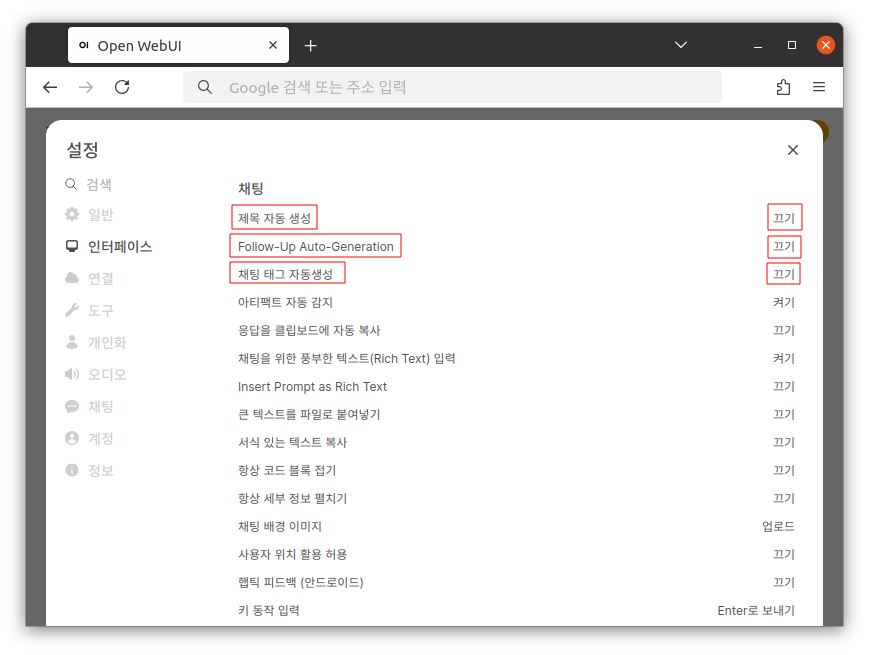
좌측 상단에 유저 아이콘을 클릭 후 설정 → 인터페이스로 이동 후 아래의 옵션을 끄기로 변경합니다.
| - 제목 자동 생성 - Follow-Up Auto-Generation - 채팅 태그 자동생성 |
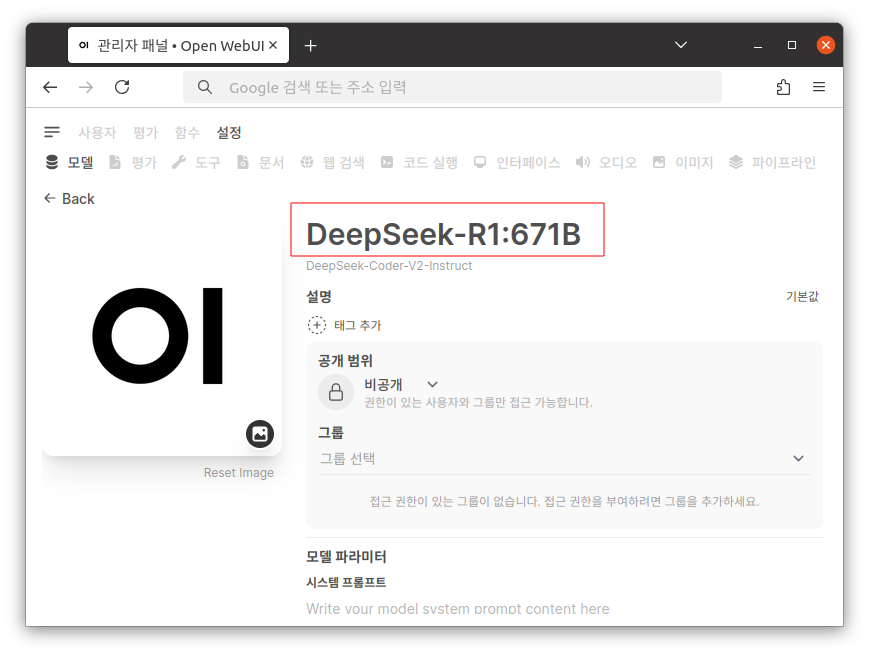
좌측 상단에 유저 아이콘을 클릭 후 사용자 패널 → 모델로 이동 후 모델의 이름을 DeepSeek-R1:671B로 변경 합니다.
|
참고사항 Ktransformers 소스상의 문제로 소스내 미리 정의된 다른 모델명이 출력될 가능성이 있습니다. 사용 시 헷갈리지 않도록 다른 버전을 사용할 때 참고하셔서 이름을 변경하시는 것을 권장합니다. |
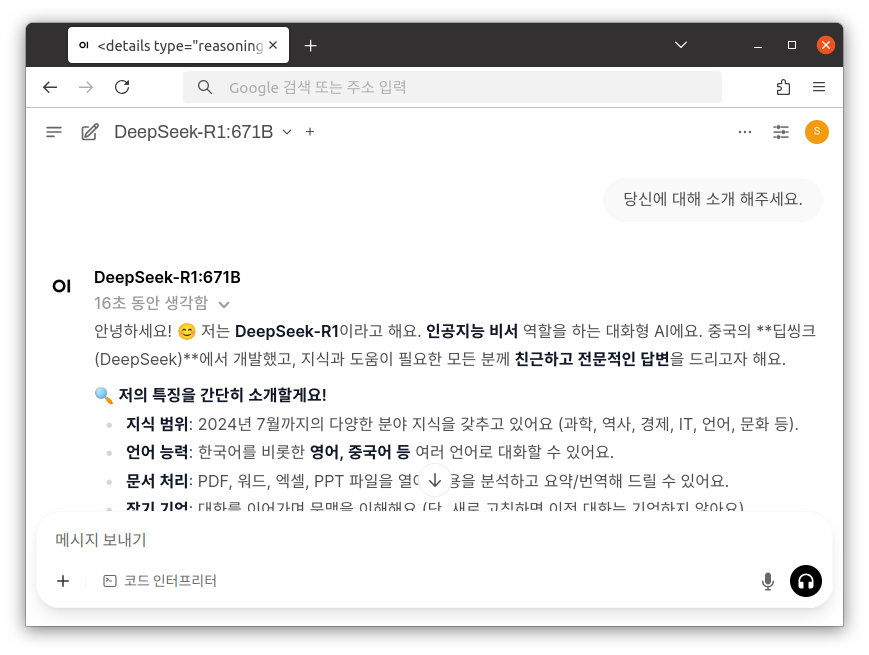
준비된 DeepSeek-R1:671B 모델을 통해 질문을 남길 수 있습니다.
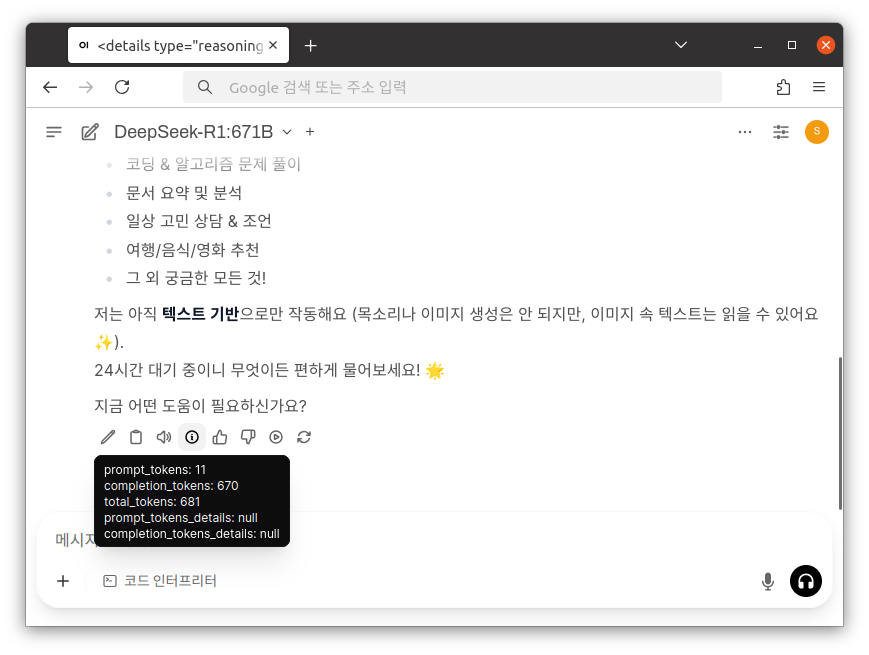
LLM 모델에 관한 성능 및 결과 값을 확인할 수 있습니다.
| 서버와 Open WebUI에 기본적으로 사용되는 22, 8080 포트에 불필요한 외부 접근을 막고 안정적인 사용을 위해서 자체적인 설정 또는 매뉴얼 통한 방화벽 설정을 적용하여 사용할 것을 권장합니다. |
|
GPU |
매개변수 |
양자화 |
크기 |
모델 구동 시간 |
DRAM 사용량 |
VRAM 사용량 |
출력 Token/s |
컨텍스트 길이 |
|---|---|---|---|---|---|---|---|---|
|
RTX4090 |
DeepSeek-R1 671B |
Q4_K_M |
404GB |
15분 |
745GB |
11.1GB |
12.4 |
128K |
|
RTX4090 |
DeepSeek-V3 671B |
Q4_K_M |
404GB |
15분 |
745GB |
11.1GB |
11.5 |
128K |
|
RTX4090 |
DeepSeek-V2-Lite 15.7B |
Q4_K_M |
10.4GB |
27초 |
28GB |
1.5GB |
72.2 |
32K |
|
RTX4090 |
Qwen2-57B-A14B 57B |
Q4_K_M |
34.9GB |
1분43초 |
66GB |
5GB |
32.7 |
65.5K |
|
4000ADA |
DeepSeek-R1 671B |
Q4_K_M |
404GB |
19분 |
738GB |
10.8G |
9.2 |
128K |
|
6000ADA |
DeepSeek-R1 671B |
Q4_K_M |
404GB |
2분20초 |
- |
11GB |
7.49 |
128K |
|
RTX5080 |
DeepSeek-R1 671B |
Q4_K_M |
404GB |
15분 |
740GB |
11.1GB |
11.6 |
128K |
|
RTX5090 |
DeepSeek-R1 671B |
Q4_K_M |
404GB |
13분30초 |
745GB |
11.4GB |
13.2 |
128K |